Baseline models demystified: a practical guide
Start simple to get far
Baseline models play a key role in every machine learning (ML) development pipeline. Let's start with an example to understand why.
Imagine you work at a company that built an online platform that has lots of active users. You know that some users love the platform and intend to continue using it indefinitely. However, after some time, other users exit the platform to never come back, i.e., churn.
Moreover, you know that by observing some of the users’ characteristics, such as age, gender, geography, and others, you could train a model that predicts whether a given user will be retained or exit. This binary classifier can be quite useful for different teams inside the organization and hopefully, if the model is good enough, specific actions can be taken in time to retain users that were likely to churn.
You understand the problem and already have labeled data. As a data scientist or ML engineer, it’s all in your hands now!
But what should you do next?
It can be tempting to start developing a complex solution right away, but that is not what your next step should be. You need to start building a baseline model!
A good baseline model takes you a long way to build high-quality ML solutions. The problem is that frequently, one of two things happen. Either a baseline is neglected completely, or a weak baseline is found in a rush, making it useless.
In many scientific fields, progress is incremental, and ML is no different. “When we lose accurate baselines, we lose our ability to accurately measure our progress over time,” as put by Smerity in their blog post.
In this post, we explore the use of baseline models in ML. First, we define what baseline models are. Then, we justify why they are useful as you develop ML models and provide a step-by-step to help you use baseline models right. Finally, we provide an example that illustrates what can go wrong when baseline models are neglected.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
What is a baseline model?
According to this blog post from Carnegie Mellon University, “a baseline [model] is a simple model that provides reasonable results on a task and does not require much expertise and time to build.”
Let’s dissect this definition.
First, a baseline is a simple model. It is important to start simple so that intuition can be built and you can start truly understanding the task at hand. Furthermore, working with simple models is particularly suitable to find bugs and test assumptions.
Second, the results produced by the baseline model should be reasonable. They are not expected to be perfect, and you will likely not use the baseline as your final model. However, if you pick any simple model without much thought, you risk wasting your time on a model that won’t help you at all.
Finally, it is important that building the baseline does not take up too much of your time. The baseline model is a starting point that will help you tremendously in the next steps of ML development, but it is not your final solution.
Why are baseline models useful?
If time is scarce, then why should you spend time building a model that will likely not serve as a final solution?
ML development is iterative. The insights that arise from one cycle inform the decisions of the next. Moreover, the speed at which practitioners iterate and learn through the stages of ML development highly dictates how well they transition from prototype to product.
Since baseline models are quick to develop, they quickstart practitioners on the ML development cycle. It doesn’t matter if the baseline model won’t be the final modeling approach. The insights that arise from its use are precious and can potentially save a lot of resources down the road.
Baselines also are a great way to increase the understanding of the data, find bugs, and test assumptions. As discussed in one of our previous posts, data is the key ingredient behind every ML solution. The process of constructing and refining a baseline model reveals a lot to practitioners in a much more digestible environment of limited complexity. Some experienced practitioners go as far as to say that “a baseline takes only 10% of the time to develop, but will get us 90% of the way to achieve reasonably good results.”
Finally, baseline models help you measure progress. ML solutions should not be more complex than necessary, and the only way to assure this is by rigorously measuring progress against baseline models. We have discussed the role of baselines for model evaluation in details in our post on model evaluation beyond aggregate metrics.
How to use baseline models in practice?
Now that you understand what are baseline models and are convinced that they are useful, it’s time to learn how to use them in practice. We break it down into five steps, but not all problems require all of them.
1. Random performance
After you understood the problem and have a dataset to start with, the first step is often conducting exploratory data analysis (EDA). This is where you would go through your raw data to get familiar with the relationships and patterns that your solution will eventually learn to explore.
What is often also useful at this stage is performing a few back-of-the-envelope calculations that should give you lower bounds on the performance. This is often done by calculating what random (chance) performance would be.
For example, if you have a binary classification task with a perfectly balanced dataset, the chance model (which outputs labels uniformly at random) would achieve an accuracy of 50%. Therefore, any modeling approach you try should at least surpass this.
Although it might seem trivial, in ML, datasets are often unbalanced, so it is not rare to have a starting accuracy in the 80-90% range for models that only output the majority class.
You should spend some time calculating your most important performance metrics (precision, recall, F1, error rates, etc.) for a random model. Anything moving forward must surpass it.
2. Rule-based
A lot of the problems currently being solved with ML had previous rule-based solutions. Before jumping to ML, when available, you should try out these solutions based on domain expertise to gauge how they perform.
It is not guaranteed that there will exist rule-based solutions to the problem you are striving to solve. However, depending on the data type, they often come from the field of signal processing or make use of auxiliary data.
3. Simple ML model
It’s time to pick a simple ML model to start. Remember, the idea is to start iterating quickly through the different stages of ML development and not to find a perfect solution.
There are mainly two aspects to consider when picking simple ML models: representation and model architecture.
The representation is related to how the data that shall be fed to the model is represented. This is less of an issue for tabular data, but if you are working with text, time series, or images, for example, there are many ways to represent them before feeding them to ML models. At this stage, favor simpler representations based on domain expertise (feature engineering) instead of learned representations (word embeddings or starting from raw convolutions).
As for the model architecture, common approaches followed by practitioners are: linear regression, logistic regression, and gradient-boosted trees. Some practitioners also start with famous pre-trained models from literature, such as ResNet for image data and RoBERTa for natural language processing (NLP), although it harms a bit the intuition development aspect of using a baseline model.
4. The limits of the simple ML model
After you started with a simple model, it’s time to push it to its limits. This means improving the baseline model performance as much as you can by testing assumptions, debugging, regularizing, tuning hyperparameters, etc.
This process will make you familiar with the data and reveal the limitations of the simple modeling approach. It will also set a strong performance baseline that you will need to surpass moving forward.
5. Gradual complexity increase
Complex models should not be built for the sake of complexity. Complex models should be used for their representational capacity. In the previous step, you’ve squeezed all the juice out of your baseline model and this should give you a decent idea about what are its limitations.
The objective now is to increase the complexity one component at a time to overcome the mapped limitations. In this process, properly conducting error analysis is key so that at every step, you are mindful of the trade-offs you are making.
Furthermore, remember the principles of data-centric AI. ML models can often be seen as statistical summaries of the data. Consequently, finding more data that looks a certain way is frequently preferable to increasing model complexity.
What can go wrong when baseline models are neglected?
To make matters more concrete, let’s look at an example of what can happen in practice when good baseline models are not used.
In 2018, a paper published in Nature used deep learning to forecast the spatial distribution of aftershocks of large seismic events. This is an important problem because the correct forecast of these locations can greatly help us not only better understand earthquakes but also improve the response to such events.
The paper used a 13k parameter neural network which, allegedly, greatly improved the performance if compared to classical estimation methods.
The issue is that a year later, in 2019, another paper in Nature showed that the same results could be achieved with a 2-parameter logistic regression. According to the latter, “this demonstrates that so far the proposed deep learning strategy does not provide any new insight (predictive or inferential) in this domain.”
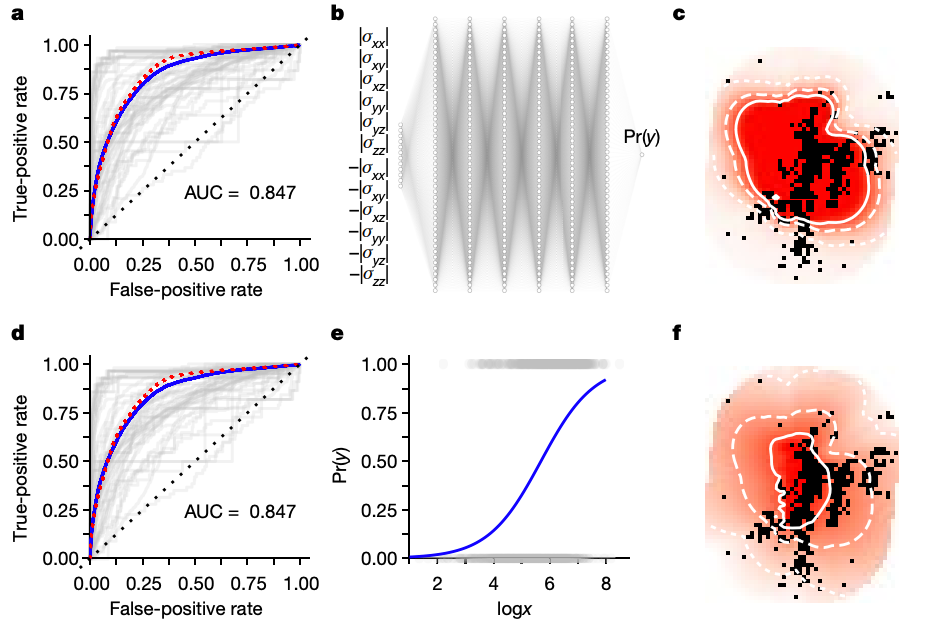
(Source: Nature paper comparing the performance of the neural net and logistic regression.)
This illustrates the importance of using good baseline models. Surpassing a weak baseline is useless, as it doesn’t indicate progress nor helps us assess if the modeling approach followed is adequate.
Conclusion
The rapid progress in the field makes it tempting to jump straight to complex modeling approaches. However, these approaches are often hard to debug, hard to interpret, and are an overkill for a lot of the problems. This is why it is important to keep both feet on the ground and start with baseline models.
Nowadays, there are a few consolidated models that are known to provide good results in practice. For example, as pointed out by Mark Tenenholtz, a senior data scientist, it can be much more productive to spend time on the data than on model architecture after starting out with a baseline:
Progress in ML is incremental, so it is key that baselines are used to measure if we are moving in the right direction with our ML models. Remember, a good baseline model gets you far and a weak baseline is meaningless.