Surefire ways to identify data drift
Avoiding silent failure in production
Data drift refers to the phenomenon where the distribution of live, real-world data differs or “drifts” from the distribution of data used to train a machine learning model. When data drift occurs, the performance of machine learning models in production degrades, resulting in inaccurate predictions. This reduction in the model’s predictive power can adversely impact the expected business value from the investment in training. If data drift is not identified in time, the machine learning model may become stale and eventually useless.
In this article, you’ll learn more about data drift, exploring why and in what ways it occurs, its impact, and how it can be mitigated and prevented.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
The importance of detecting data drift
Machine learning models operate in a dynamic environment but are trained on data from a fixed, statistical distribution. Data drift can occur due to a variety of reasons, including seasonal variations, new product features, changes in customer behavior, or even rare events like the Covid-19 pandemic.
Data drift is a critical challenge for production machine learning systems. It occurs when the statistical distribution of the target or real-world data diverges significantly from the statistical properties of the data on which the model was trained. This hurts model performance on new unseen data during real-world inference, leading to inaccurate predictions, poor customer experience, and monetary and reputational costs for the business.
If undetected, data drift can cause multiple problems besides the obvious loss in model performance. It leads to greater MLOps challenges and technical burden for teams such as identifying data drift, conducting root cause analysis for input features correlated with data drift, data labeling, active learning, retraining, and redeploying the updated models to production. This is a significant investment of time and resources that can be avoided if machine learning models are closely monitored and a strategy for detecting and fixing data drift is in place.
How to identify data drift
It is common to assume that a loss in model performance may be due to data drift. However, before arriving at this conclusion, it is important to assess data quality. Target data distributions could change due to a new set of users, a feature or product update, or even something as simple as a bug or formatting error in the code or data. After data-quality issues are ruled out, data drift can be examined in more detail.
Fundamentally, data drift implies a change in the statistical distribution of target data from that of the training data. Thus, the simplest way to identify data drift is to compare summary statistics (like mean, variance, Kullback–Leibler divergence, and so on) of a carefully sampled subset of the target data against the training data. Other statistical measures include comparing the number of outliers in the two distributions or using the Kolmogorov–Smirnov test. Analyzing the correlations between input features and model predictions for both the data distributions can also shed some light.
Model-based machine learning techniques can also be used to identify data drift. A sample of data from the reference or training distribution can be labeled as 0, and an equivalent sample from the target distribution can be labeled as 1. Based on this input data, a simple binary classification model can be trained to discriminate between the two types of data distributions. If the model can distinguish between the two data sets, this implies that data drift is present. Alternatively, if the model fails to discriminate between the data sets, then no data drift is evident. Using a machine learning–based approach captures nonlinear relationships better and can help catch data drift where the above statistical methods might fail.
What are the different kinds of data drift?
The change in the statistical distribution between the target and training data manifests in different forms of data drift that are observed in real-world machine learning systems:
Covariate shift (feature drift)
Covariate drift refers to a data drift that is correlated with a shift in the independent variables or input features. The relationship between the features and target variables is unchanged, but the change in a few features leads to covariate drift. Covariate drift can occur due to sample selection bias and is frequently observed in nonstationary environments.
Concept drift
Concept drift is associated with a change in the relationship between the independent variables and the target variables. For instance, a particular machine learning model may suffer from concept drift when it is launched in a new geography where the customer behavior is markedly different from the behavioral data from the original geography that was used to train the models. Although the set of input features and the data distributions may remain the same, the model may not make any useful predictions and is rendered obsolete.
What does data drift look like?
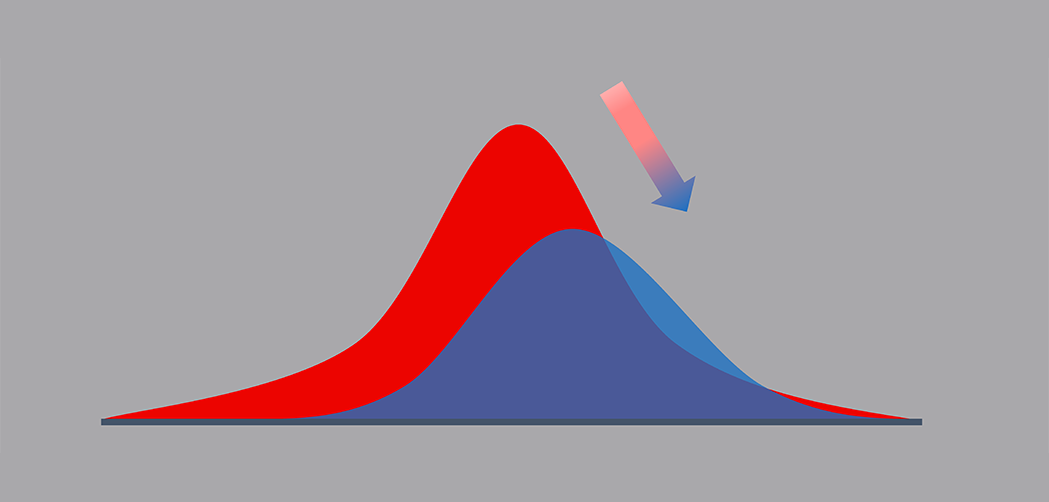
Image source - EvidentlyAI, "Machine Learning Monitoring, Part 5: Why You Should Care About Data and Concept Drift"
As shown in the image above, typical data drift can be captured by analyzing the shift in the statistical characteristics of the target data distribution relative to the reference data distribution. Statistical tests can be performed to evaluate whether the data drift is actually statistically significant or meaningful enough to intervene.
Another way to visualize data drift is to continuously monitor the machine learning model in production and plot performance metrics, like precision, recall, or F1-score, over time for both the reference data as well as the target real-world data. Any significant change in the model metric that diverges beyond established performance thresholds may be indicative of data drift.
How can you mitigate and prevent data drift?
Once data drift is confirmed as real and significant after rigorous analysis and statistical tests as described above, it is important to address it sooner than later. Here are a few strategies for doing so.
Data labeling
Labeling the new target data is the first step toward addressing data drift. A carefully selected batch of the test data can be sampled and sent to subject matter experts for data annotation. Thereafter, this labeled target data from the modified data distribution can be incorporated into the original data distribution to ameliorate the impact of data drift.
Periodic model training
With newly labeled target data, the model can be retrained on data from both the original distribution and the test distribution. As the new model is now trained to recognize data from the modified target distribution, it typically does a better job in production than the original model. However, a model might need to be trained multiple times, depending on the rate of data drift, to capture the new patterns from the test data.
Model recalibration
With repeated model retraining, the training pipeline, model architecture, and hyperparameters may remain the same, with the only difference being the change in training data. However, if data drift is not taken care of with periodic retraining, it might be prudent to train the model from scratch with a fresh approach and insights learned from efforts focused on evaluating and mitigating data drift.
The new model may be trained differently from the original one in a number of ways:
- Reweighting the more recent data samples;
- Conducting error analysis to identify any segments on which the model fails consistently;
- Testing different model architectures depending on the machine learning use case;
- Evaluating model-adaptation strategies to fit the model to a new target domain.
Continuous monitoring
Continuous monitoring of machine learning model performance is critical to keep track of the quality of the model in production. Model performance metrics like true positives, false positives, precision, recall, F1-score, and AUC-ROC curves can be periodically assessed. After thresholds for such performance metrics are carefully selected, alerts can be triggered using platforms like Grafana or Prometheus or by using third-party-managed MLOps platforms.
Apart from output metrics, other things to monitor include any data issues or inconsistencies, bias in training data, and explainability metrics.
Conclusion
The phenomenon of data drift afflicts most machine learning models in production, arising from various reasons due to the dynamic nature of real-world data, seasonal trends, changes in product features, software- or data-related issues, changes in customer behavior due to new competition or legislation, and even rare black swan events like the Covid-19 pandemic.
Data drift can be of different types, depending on whether the relationship between the independent features and the target variables changes or not. This article has equipped you to know what data drift looks like and provided a list of best practices for identifying and mitigating it before it becomes a major MLOps challenge and renders the machine learning model unfit for its intended business purpose.


