The roads toward explainability
Shedding light on black-box ML models
Interpretability and explainability are terms that have pervaded the field of machine learning (ML) in recent years. At first sight, they seem to convey intuitive notions of desirable characteristics of ML models. However, a second more attentive look reveals that these are underspecified concepts, as pointed out by Lipton.
After all, what does it take for a model to be interpretable? Does it mean that humans can understand all the low-level details of a model? Or does it simply mean that humans fully trust it?
Even though there is no precise definition of what it entails, interpretability and explainability are extremely useful in practice. They help shed light on black box models by starting to paint a picture of what has actually been learned. Furthermore, practitioners must look beyond aggregate metrics if they desire to build performant and trustworthy models.
Then, how does one understand what a model has learned?
Many roads lead practitioners closer to this objective. In this post, we will explore some of them, presenting common methods that can be used in practice.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
Post-hoc explanations
Methods: SHAP, LIME, Anchors
At the highest level, it is possible to classify interpretability methods as either intrinsic or post-hoc.
Intrinsic methods refer to ML models that are naturally interpretable to humans. For example, a linear regression that relies on a few features is intrinsically interpretable, as the model’s weights can be inspected and seen as a measure of feature importance. The same can be said about shallow decision trees: the feature space partitions that comprise a decision tree encode easily interpretable rules.
But what happens when using high-dimensional features or deep trees? Intrinsic interpretability is not absolute, and past a certain threshold, even these models are no longer interpretable to humans.
In contrast, post-hoc methods are applied to ML models after they are trained to help explain why they behave in a particular way. Post-hoc explanations are useful because one can use any model and then generate explanations for individual predictions afterward instead of having to work only with intrinsically interpretable models and their limited predictive capabilities.
Some of the most popular post-hoc explainability techniques strive to find interpretable models that approximate parts of the black-box model, known as surrogate models. SHAP and LIME are both methods that make use of linear models to explain the predictions of complex ones. Anchors is a method that makes use of rules (decision trees) as explanations.
Similar examples
Methods: K-nearest neighbors, influential instances
Humans often make sense of the world through analogies and examples. For instance, when someone faces an issue, they might recall similar situations they faced in the past to make up their mind about how to proceed.
ML models’ predictions can also be explained by making use of similar examples. The idea is to retrieve samples from a dataset that were either particularly influential to the model or for which the model is making similar predictions.
For example, if a fraud classification model is predicting that a particular sample is fraudulent, finding other similar samples on the dataset and putting them side-by-side might help practitioners understand why their model is behaving the way it does.
There are many methods that either implicitly or explicitly make use of these ideas. K-nearest neighbors is an ML model that is explicitly based on this idea. After a model makes a prediction, one might have a look at some of the nearest neighbors of a sample to check for similarities. Influential instances are another possible path toward finding informative examples.
The caveat is that for such explanations to be useful, the data format must have meaning for humans. For instance, if the retrieved data samples are images, phrases, or tabular with a few features, they are informative to practitioners. However, if the retrieved samples are tabular with thousands of features or for which the features themselves are not interpretable, they are of little value.
Dissimilar examples
Methods: counterfactual and adversarial analysis
The previous category of techniques focused on finding similar data samples on a dataset to tap into the “understanding by analogy” way of thinking. However, this is not the only way humans understand the world. Another powerful way of understanding a situation is by contrasting distinct situations, i.e., with dissimilar examples.
Humans particularly like contrastive explanations. We are geared toward understanding a situation by contrasting two objects side-by-side. An example from the book “Interpretable machine learning: a guide for making black box models explainable”, by Cristoph Molnar, illustrates this point well: a physician might wonder why a particular drug did not work for their patient. A contrastive explanation might be along the lines of “in contrast to the responding patient, the non-responding patient has a certain combination of genes that make the drug less effective.”
Applying such an idea to ML gives rise to techniques such as adversarial and counterfactual examples. Instead of finding similar examples on a dataset, we are interested in either finding or coming up with data samples for which the models’ predictions are different than the one we are investigating.
The ideas of counterfactuals and adversarial analysis are also applicable to testing ML models. Exposing the models to examples specifically constructed to fool them is a great way to ensure robustness and not be surprised by hidden failure modes only after deployment, as we explored in our posts on ML testing and error analysis.
Explainability and error analysis
Error analysis is the stage in the ML development cycle where practitioners strive to understand when, how, and why their models fail. It embraces the process of isolating, observing, and diagnosing erroneous ML predictions, thereby helping understand pockets of high and low performance of the model.
In this process, the various explainability techniques play an important role. Each one is capable of providing a distinct perspective about the model, thus, revealing what are the next steps to boost model performance.
To make matters more concrete, let’s go through a few examples.
First, let’s look at the LIME scores in the context of a multi-class classification problem with natural language processing (NLP). In this task, we are interested in classifier user inquiries into one of many categories.
With Openlayer, practitioners can have a look at the LIME scores for a sample by clicking on a particular row.

Each token receives a score. Values shown in shades of green indicate the tokens that contributed to the model’s prediction toward the correct direction. Values shown in shades of red indicate the tokens that contributed negatively to the model’s prediction, pushing it in the wrong direction. Therefore, it is important to remember that these values are always relative to the true label.
In this specific example, the user simply wanted to get a spare card (the true label is getting_spare_card), but the model thought it was from the class card_linking. Notice that the words “card” and “linked” really pushed our model’s prediction in the wrong direction, that’s why our model got it wrong.
At the end of the day, the model’s prediction is a balance between features that push it in the right direction and features that nudge it in the wrong direction.
Error analysis needs to be a scientific process, incorporating hypothesizing and experimenting to its core. That’s one of the roles of the what-if analysis.
To conduct a what-if analysis with local explanations, we can simply edit the sentence and click on What-if, at the bottom of the page. For example, if we rephrase the original sentence to “How can I create another card for this account?”, what would our model do?

Now we can directly compare the two explanations. Notice that by simply rephrasing the problematic sentence, our model was able to correctly classify it. This might be an indication that our model could benefit if we augment our training set using synonym expressions.
Let’s now consider the path of dissimilar examples presented in another ML task.
Using a churn classifier as an example, we might wonder what it takes to flip the model’s predictions from Retained to Exited by perturbing the feature Age. Here are a few adversarial examples we obtained with Openlayer:
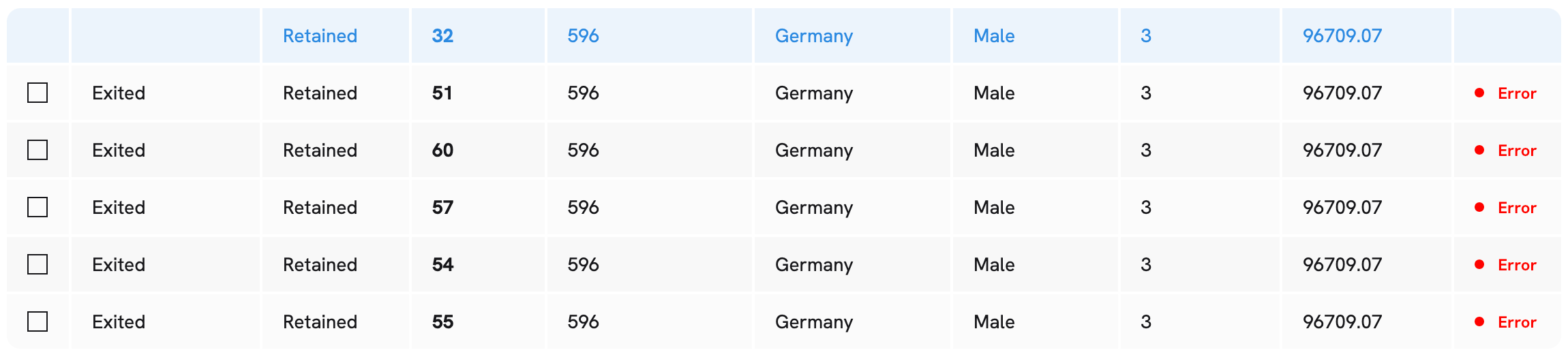
Notice that by perturbing the age, and keeping all the remaining features unchanged, we were able to flip the model’s predictions. This does not necessarily mean that the model is making mistakes, as further investigations would be required to get to the ground truth about the adversarial examples. What it does inform us, however, is that the feature age seems to have a big role in the model’s predictions. Depending on the task at hand, that might be expected or it might be a symptom of over-indexing.
Many roads lead practitioners closer to understanding their models. Incorporating multiple dimensions of explainability into error analysis procedures is a great practice, from which actionable insights arise naturally. If you are interested in understanding what’s going on under the hood for your ML models, head straight to Openlayer!
* A previous version of this article listed the company name as Unbox, which has since been rebranded to Openlayer.