What is data-centric AI: 3 reasons to pay attention to it
The trend in AI
At every instant, massive volumes of data are being produced and, as John Naisbitt puts it, “we are drowning in information, but starved for knowledge.” To make sense of and leverage all this information, we must be equipped with the right tools.
Enter the world of machine learning and AI.
AI/ML as disciplines have the potential to give us a powerful toolkit that aids in the process of extracting meaning from this ocean of data. Not only that, but AI/ML models often thrive in such environments where the amount of data is way beyond what we, as humans, can intuitively grasp.
Unfortunately, it’s not all sunshine and rainbows.
Bridging the gap between information and knowledge is not a simple task. Working with AI models is challenging and the whole process involves a cascade of decisions with consequences that are not completely evident at first.
For example, let’s say you have developed an ML model and the performance you observe is below what you want (and need) it to be. Which knob should you turn to boost your model’s performance?
Should you use a completely different modeling approach? Should you use a different set of features or pre-process them differently? Or would it be better to change the loss that your model optimizes for?
Notice that there are far too many possibilities and the mere process of listing all of them is overwhelming.
More often than not, what happens in practice is that the model takes almost all of the blame when things don’t work out as expected. The model wasn’t able to capture all the complexity present in the data is just one variant of the verdict the models end up receiving. The envisioned solution, then, is changing the model.
Teams continuously jump between modeling approaches. From classical ML to deep learning. From deep learning to exotic combinations of models and losses someone came up with last week on arxiv.org.
When we stop and critically think about the above situation, it is straightforward to recognize that indeed the modeling approach is sometimes the culprit. But is it always the case?
Certainly not. This line of thinking is a symptom of a model-centric approach, currently pervasive in the field of AI/ML. Nowadays, the most popular approach to solving ML tasks is to hold the data fixed and iteratively improve the model until the desired results are achieved. But this is not the only possibility.
Stanford professor, Andrew Ng, recently launched the data-centric AI campaign. He argues that the process often followed by the industry must be transformed. According to him, a more effective approach to get the right results is the opposite: holding the model fixed and iteratively improving the data quality.
In this post, we explore three main advantages associated with following a data-centric approach when compared to a model-centric approach.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
Good data > Big data
We live in the age of big data. Therefore, in industry, there is frequently a false notion that having more data is the solution to most ML models’ problems.
The motivation behind such a claim comes, partly, from the recent successes of deep learning, where enormous models with millions or even billions of parameters fed with massive amounts of data were able to beat the state-of-the-art in various benchmarks.
However, it is becoming increasingly clear that good data is much better than big data. Simply getting more data for the sake of it might do more harm than good if the additional data does not have a high quality, e.g., outdated data or mislabeled data. Furthermore, not all models need to learn as many parameters as the famous neural network architectures that occupy the pole position of the benchmarks, which is the main reason they large datasets.
With a data-centric approach, the idea that good data is paramount becomes a reality. Practitioners can focus on constructing high-quality and representative datasets, abandoning the simplistic idea more data is the solution to all of their problems. As a result, more often than not, managing the data becomes simpler, as dataset size decreases.
Boost model performance one slice at a time
We want models that perform well for not only whole datasets but also for every potential edge case it might encounter out in the wild. The problem when we strive to achieve that goal, it is easy to be overwhelmed by the number of possibilities and suffer from analysis paralysis.
A better and more realistic approach would be to increase the model’s performance one slice of data at a time.
The idea is that by focusing on one digestible chunk of the data at a time, we can understand what might be our model’s failure mores and how to address them, systematically improving the model’s performance gradually.
According to Andrew Ng, the lifecycle of data-centric AI follows these steps: train the model, conduct error analysis to identify the type of data the algorithm does poorly on, either get more of that data via data augmentation or additional data collection or give a more consistent definition for the data labels if they were found to be ambiguous.
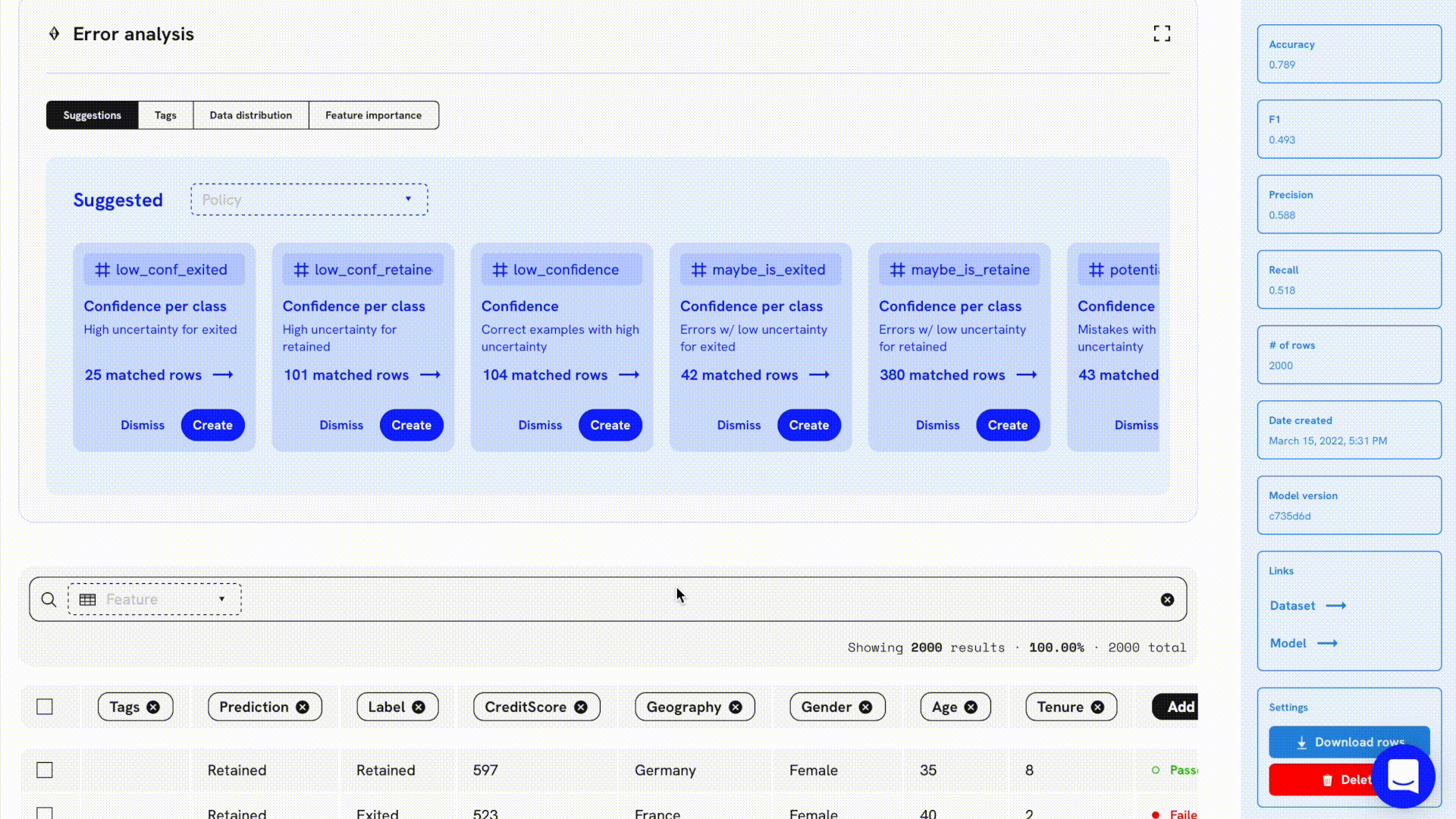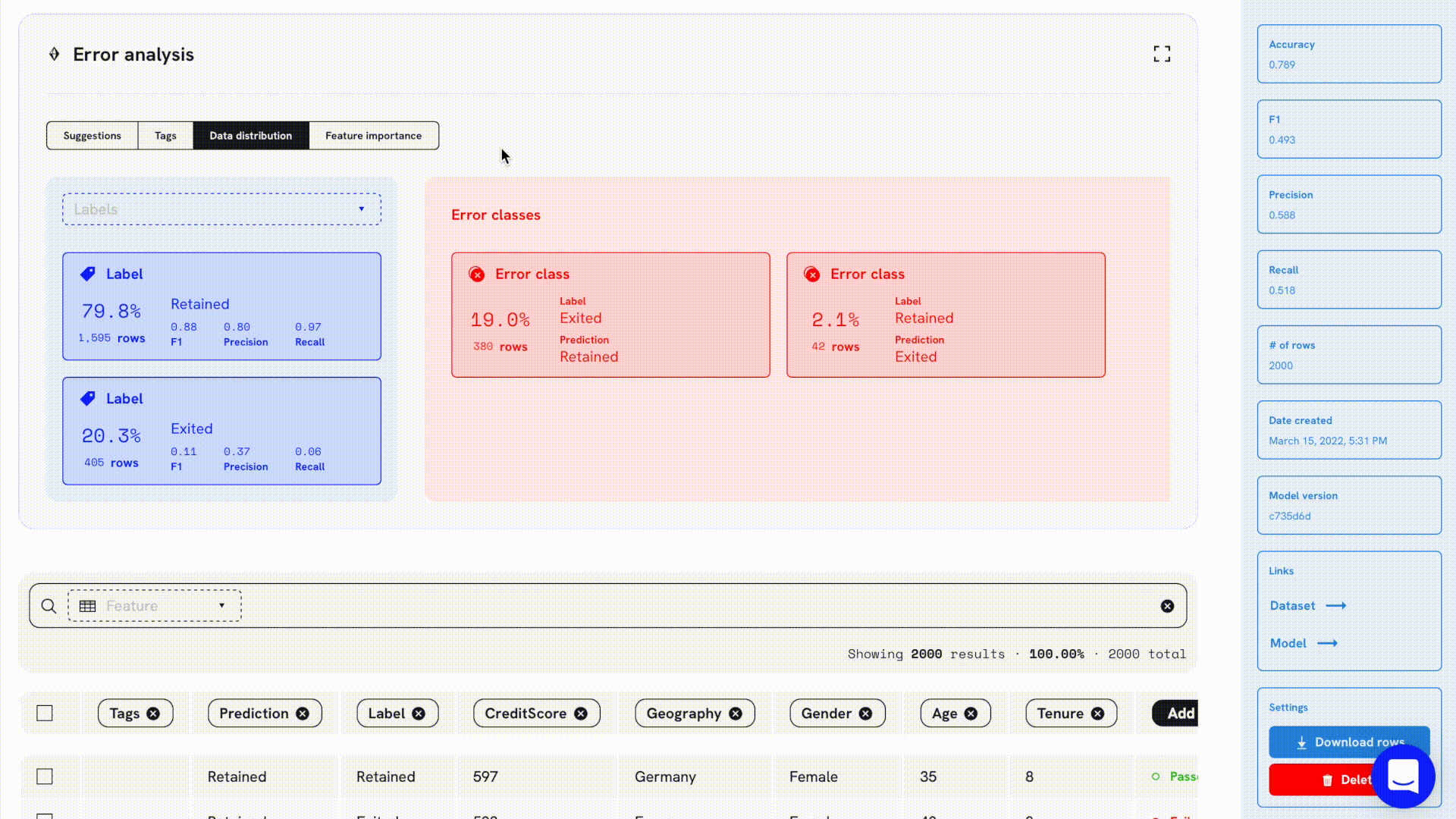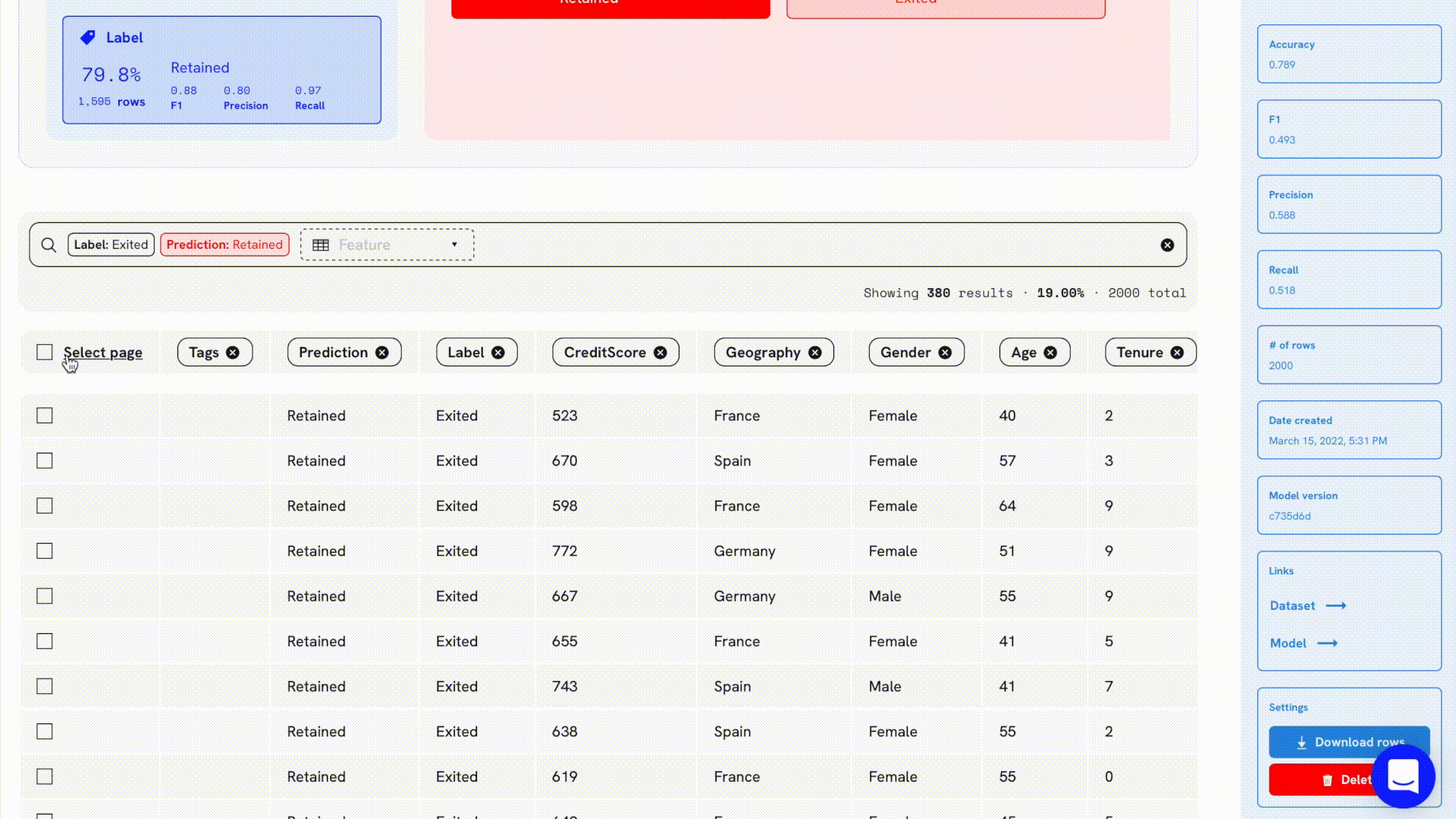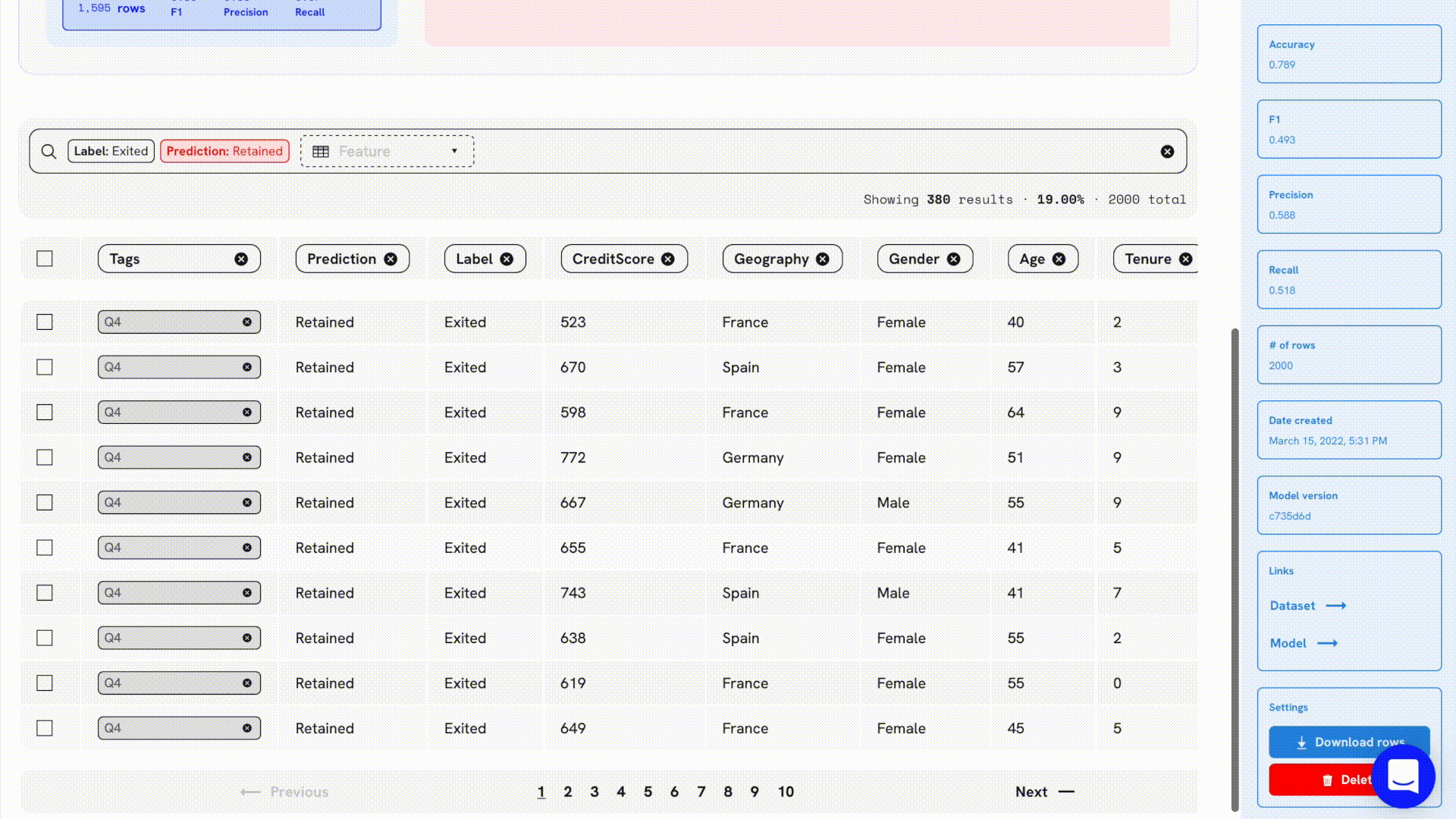
The idea of improving models one slice at a time was one of the key motivations for the easy filtering and tagging features at Openlayer. By quickly filtering through the error classes that happened in our validation set and tagging them a certain way, teams can collaborate and focus on improving model performance on digestible chunks.
For example, let’s say we have a model that predicts whether a user will churn or not based on a set of features and we upload it with a validation set to Openlayer. We can quickly notice that most of the errors occur when the model mispredicts a user will be retained. We can filter that data slice and tag. By doing so, all team members can know exactly which data slice is currently in the spotlight, not to mention the other functionalities available which are based on tags, such as testing, generating synthetic data, and others.
Commoditized models
A lot of the popular models can be seen as commodities. Using libraries such as scikit-learn or TensorFlow, everyone is only a few lines of code away from model architectures that win competitions on Kaggle.
This should be enough to make clear that model architecture alone doesn’t take teams very far. Then, what differentiates the winning models in the real world?
It’s all about the data. We forget that models can often be seen as statistical summaries of the data. That means that without good data, learning is doomed to fail.
Even though models can be seen as commodities, available to everyone, it is much harder to commoditize training data. Training datasets emerge from a messy process, particularly tailored for that specific application’s needs.
Therefore, having the right data for your application can be your competitive advantage.
The transition from model-centric to data-centric approaches is an undergoing paradigm shift in the field of ML. However, they are not meant to be mutually exclusive. With this post, you now have a few reasons to start thinking seriously about data-centric AI approaches, which are powerful yet often neglected in the industry. This is a topic that we deeply care about at Openlayer.
* A previous version of this article listed the company name as Unbox, which has since been rebranded to Openlayer.