Powerful testing, evaluation, and observability for LLMs
No more guessing whether or not your prompt is good enough. Treat your LLM product like traditional software development.
1. Push your workflow with a few lines of code
1
import os2
3
os.environ["OPENLAYER_API_KEY"] = "API_KEY"4
os.environ["OPENLAYER_PROJECT_NAME"] = "NAME"5
6
from openlayer import llm_monitors7
8
# With publish=True, every row is published to Openlayer9
monitor = llm_monitors.OpenAIMonitor(publish=True)10
monitor.start_monitoring()2. Create tests

3. Keep track of your progress

Iterate on agents usingcustom workflowsor direct API calls

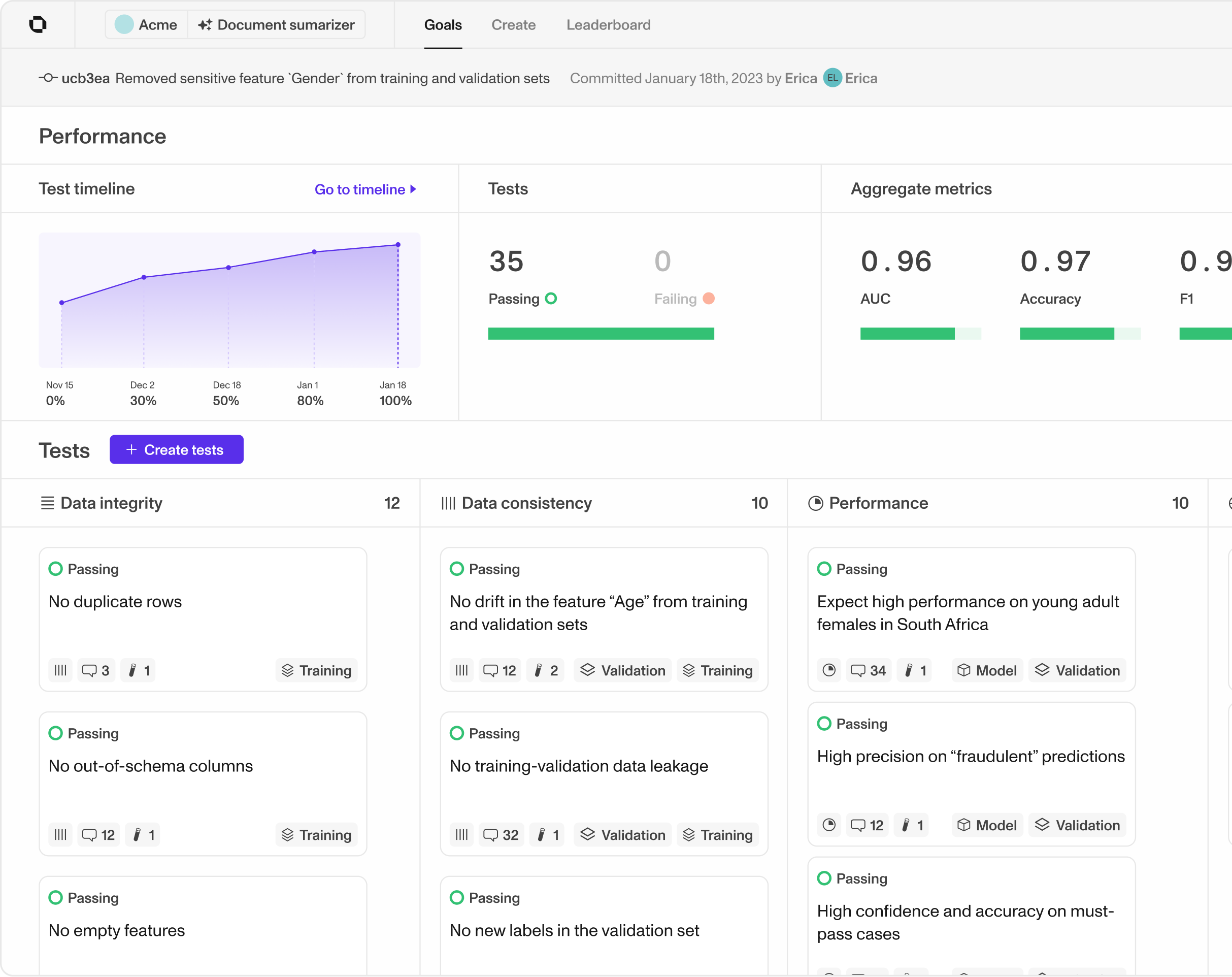
Automatic testing for your models
Choose from our suite of data quality, drift, and performance tests. They run on each version of your model and data, so you always know where you stand.

Monitor with real-time alerts
Keep a close eye on your models in production and receive alerts wherever you spend your time — email, Slack, or in the Openlayer app.
Openlayer
Deployment status changed
To 🟢 Ready to deploy From 🔴 Not ready
Openlayer
@sophia commented on No duplicate rows
– thoughts on changing the threshold?
Openlayer
Test status updated for No output drift
To 🔴 Failing From 🟢 Passing

Track and version
Say goodbye to disorganized folders and spreadsheets. All your models, datasets, and prompts live in a familiar commit system so you can effortlessly track and compare versions.
Designed to be developer-first
60-second onboarding
Upload your models and datasets straight from your training notebooks or pipelines. With one simple call to our API, your models are auto-magically loaded and deployed.

Commit-style versioning
Effortlessly track every change, just like you do with code. Our commit-style versioning system enables quick, continuous iteration on your models.

Seamless notifications
Stay in the loop without breaking your workflow. Receive real-time updates on model performance, data anomalies, and team activities directly to Slack, email, or in-app.
Openlayer
@sophia commented on No duplicate rows
– thoughts on changing the threshold?
Openlayer
Test status updated for No output drift
To 🔴 Failing From 🟢 Passing
Secure deployment
Secure your data with our SOC 2 Type 2 compliant platform and on-premise hosting option. Take control of your models and datasets, ensuring they never leave your infrastructure.

What others are saying
Debugging error cases is the highest leverage way to improve ML systems. Openlayer makes it easy to debug those cases and, more importantly, helps fix them as well. I highly recommend using it in all ML workflows
Gautam Kedia
Head of Fraud ML at Stripe
The Openlayer team deeply understands the challenges faced by the ML community. Their platform is the best way to streamline the evaluation and analysis of models to drive continuous improvement in AI.
Max Mullen
Founder of Instacart
Openlayer is building the critical infrastructure for the safe deployment of AI at planetary scale.
Guillermo Rauch
Founder & CEO of Vercel
Openlayer has been a valuable asset to our team. The platform's timeline feature is excellent for tracking progress, and collaborating has become effortless. This is a top-notch platform for gaining insights into ML models.
Rishabh Gupta
Lead Data Scientist at Zuma
I've witnessed first-hand the critical importance of error analysis in the world of machine learning. The Openlayer platform can save countless debugging hours and significantly improve model performance for data scientists worldwide.
Mark Belvedere
Data Science Director at Meta
Openlayer is a unique, data-centric ML solution that supports test-driven development and data quality analysis. This tackles a critical problem around ML data intelligence that only grows with the increased ubiquity of AI.
Astasia Myers
Enterprise Partner at Quiet Capital