Detecting data integrity issues in machine learning
Methods and tools for data quality assurance
When it comes to machine learning (ML) model development, a lot of weight is often placed on choosing the most suitable model.
However, as we have previously explored in our data-centric blog post, data is the substrate on top of which high-quality models are built. Without good data, learning is doomed to fail.
In this post, we explore data integrity in the context of ML. We define what data integrity is and why it matters for ML practitioners. Then, we provide practical approaches that everyone should follow to detect and prevent data integrity issues in their datasets.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
What is data integrity?
Data integrity refers to the accuracy, consistency, and reliability of data. In broad strokes, it can be seen as one of the aspects of data quality.
Data is dynamic and, consequently, integrity issues can arise at various stages of the data lifecycle. Furthermore, it can manifest in different shapes and forms.
For example, data can be inaccurate or incomplete when it doesn’t provide a truthful representation of the world. It can be duplicated when some events that happened only once in the world are registered multiple times, or it can also be invalid when it paints an impossible picture.
Given its importance and variety, it is clear that maintaining data integrity requires a proactive approach.
Why data integrity matters in ML?
Data integrity is not a new topic in traditional data systems. But how does it fit within the context of ML?
An ML model is designed to learn useful patterns from data. When that data is plagued with integrity issues, several problems arise. Not only does learning become more challenging, but the model may also end up relying on spurious patterns that are irrelevant or even misleading.
This is why industry professionals often say that “ML models are only as reliable as the data used to train them” or that in ML, when you put “garbage in, you get garbage out.” These sayings emphasize the importance of using high-quality data the goal is to build high-quality models.
Data integrity issues in the training set can have far-reaching consequences. For instance, problems such as poor performance in specific subpopulations or biased predictions can often be traced back to data integrity issues. In such cases, the data used for those subpopulations may be inaccurate or incomplete, leading to skewed results and undesired biases.
The validation set is also not immune to data integrity issues. In that case, evaluating models using such datasets can be misleading. For example, consider a validation set that contains duplicate rows. If the model happens to predict all the duplicates correctly, the resulting aggregate metrics will be overly optimistic, masking potential underlying problems. On the other hand, if the model struggles with the duplicates, the aggregate metrics will be overly pessimistic. Since the insights that arise from model evaluation are crucial to determine the next steps of model development, it is easy to see the potentially catastrophic consequences of making decisions based on false information.
How to detect and prevent data integrity issues?
Now it should be clear that data integrity must be a first-class citizen when building ML models. But how can you detect and prevent it?
Oftentimes, data integrity issues originate from the data collection process. Therefore, the first step is understanding where the data comes from, the path it takes, and how labeling happens. For example, if your dataset is manually labeled, it is important to make sure that all of the labelers are following a set of well-defined directives. Otherwise, inconsistencies certainly will arise and negatively affect model learning.
In addition to understanding the full data lifecycle, it is important to recognize that the datasets used in ML are ever-evolving. Training and validation sets are constantly being updated to reflect the current state of the world. Thus, it is important to set up guardrails that automatically check for data integrity issues. If these guardrails are not in place, there is a high risk that integrity issues are introduced from one version to the next and silently affect model development. You can think of these guardrails as unit tests on data integrity.
Let’s go through a few practical examples of data integrity tests that, despite their simplicity, can save a lot of debugging time downstream.
Duplicate rows
What happens if you have duplicate rows in a dataset?
In the training set, the model will place more weight on the duplicated examples. In the validation set, the aggregate metrics will be distorted and misleading.
A common cause for duplicate examples is data pipeline issues. In the process of moving data from the source, through transformations, up to the point when it’s ready to be used by ML models, multiple versions of the same sample might slip through.
Therefore, checking for duplicate examples is simple yet incredibly important.
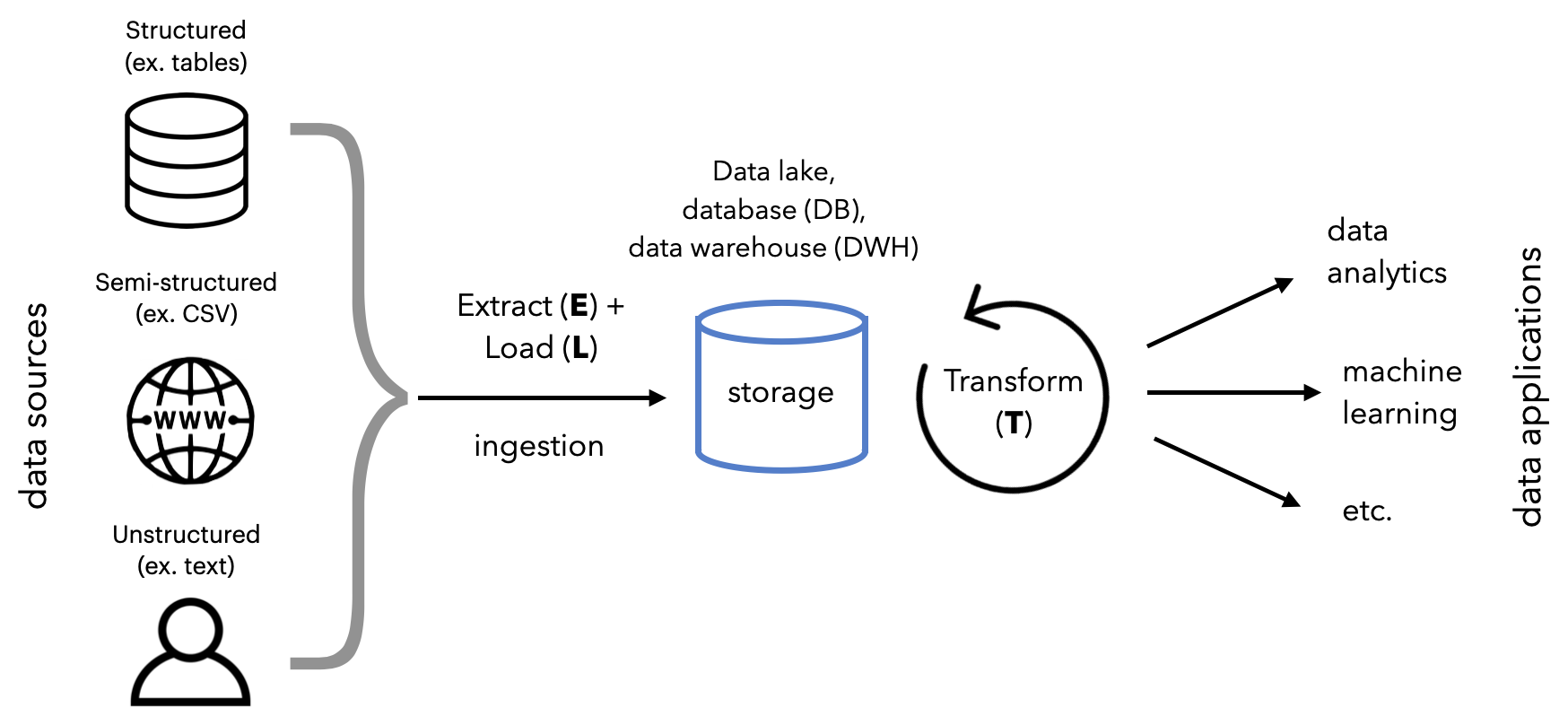
(Example of the path data takes from data sources to ML applications, from MadeWithML)
Conflicting labels
ML models are trained to map inputs to outputs. What if your dataset contains samples with identical inputs but with different labels for each?
This is what we call conflicting labels.
In this case, ambiguous data is provided to the model, which hinders model learning.
The solution is to disambiguate the samples with conflicting labels. In manually labeled datasets, the ambiguity might have been introduced by the labelers. In tabular datasets, conflicting labels might be a symptom of not using enough (or the right) features. After all, the samples could indeed come from distinct events in the real world, but their feature representations end up being identical.
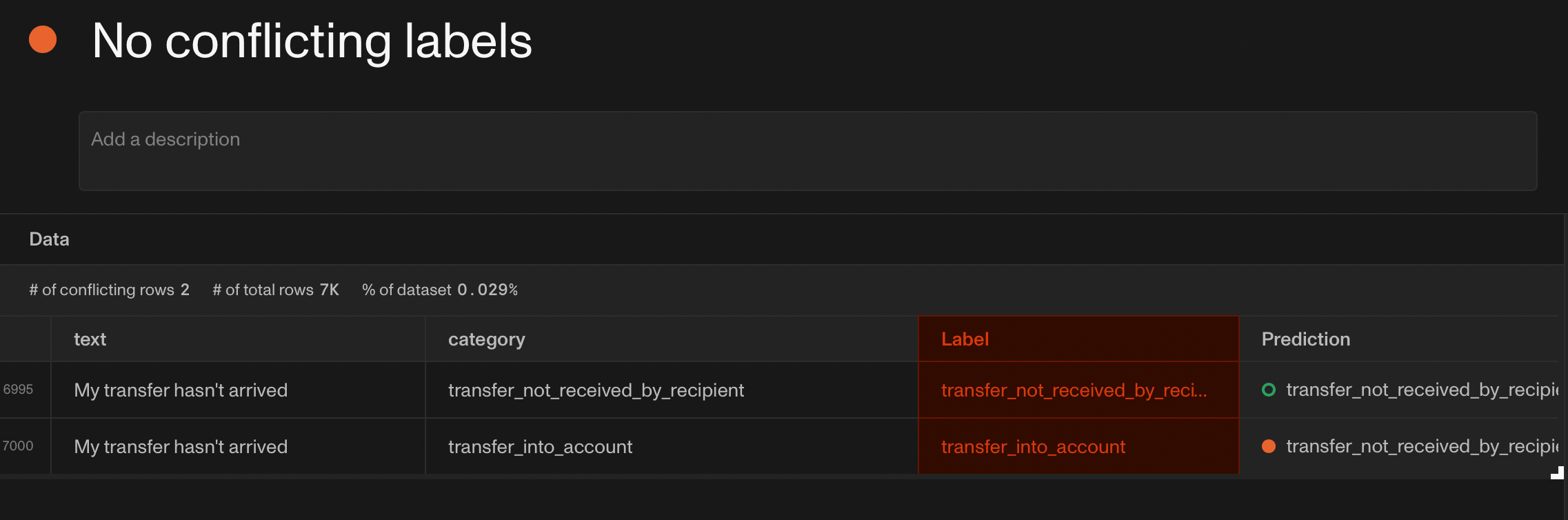
(Screenshot from Openlayer)
Feature value ranges
Tests for feature value ranges are particularly important for tabular tasks in ML. The idea is to ensure that the feature values are indeed correct and there aren’t issues that make them invalid.
For example, a feature such as Age should be an integer greater than 0. If a dataset contains a negative age, that sample is invalid. The ranges can also be application-specific. If a team wants to train a model specifically for users with a high CreditScore, ensuring that both training and validation sets contain data where CreditScore is within the expected range is important.
While you want your model to be robust to outliers (which generally should not be discarded, but rather, treated), here, we are talking about guardrails that define valid and invalid data.
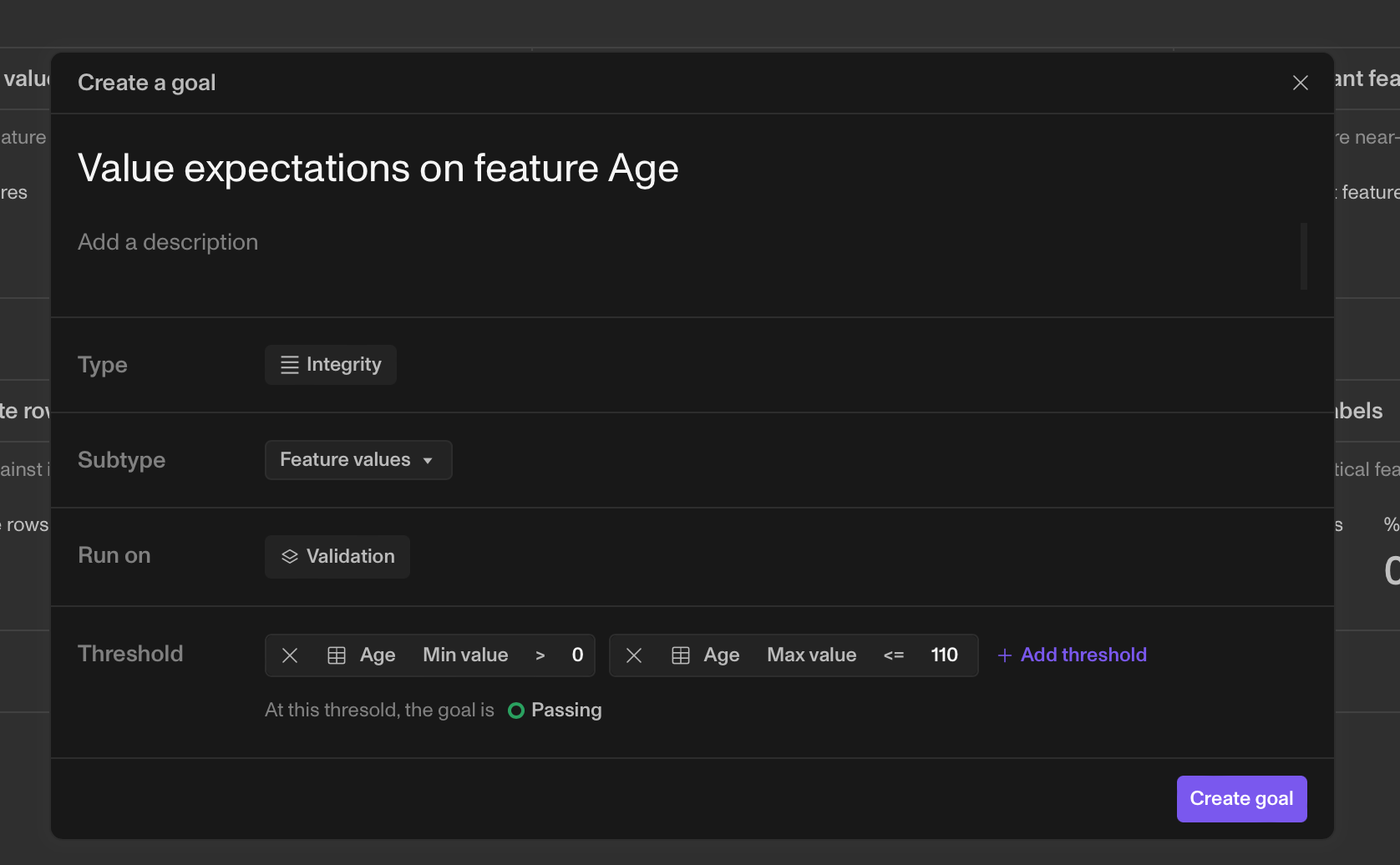
(Screenshot from Openlayer)
Missing values
Missing values are a constant companion of ML practitioners. Not only figuring out the best way to treat missing values is important but also having checks in place to ensure the dataset conforms to what is expected.
To define the acceptable level of missing values, it is important to keep in mind the different types of missing values and which ones apply to your use case. Namely, if values are missing not at random (MNAR), missing at random (MAR), and missing completely at random (MCAR).
The discussion of each type of missing data is out of the scope of this post, but the interested reader should check out their full definition in detail on this NIH page.
It is not uncommon to come across tabular datasets with most (if not all) values missing for a few features. Particularly if such datasets contain many features that are not interpretable. Having checks for acceptable levels of values missing ensures that such features don’t go unnoticed.
Feature variability
Ideally, every feature in the set of features used by a model should contain useful information for the task at hand. Otherwise, why use it in the first place?
A good check that often reveals features that contain little information is the feature variability test.
We define as quasi-constant the feature whose variance is very small. Quasi-constant features provide almost no information for the model. After all, it is almost identical for every sample of the dataset.
On the other end of the spectrum are the index features: features that contain a different value for every row of a dataset. These features are also not particularly useful for the model, since they help little with discriminating between the samples.
Of course, there are exceptions, so it is important to think critically about your use case and if such guardrails make sense.
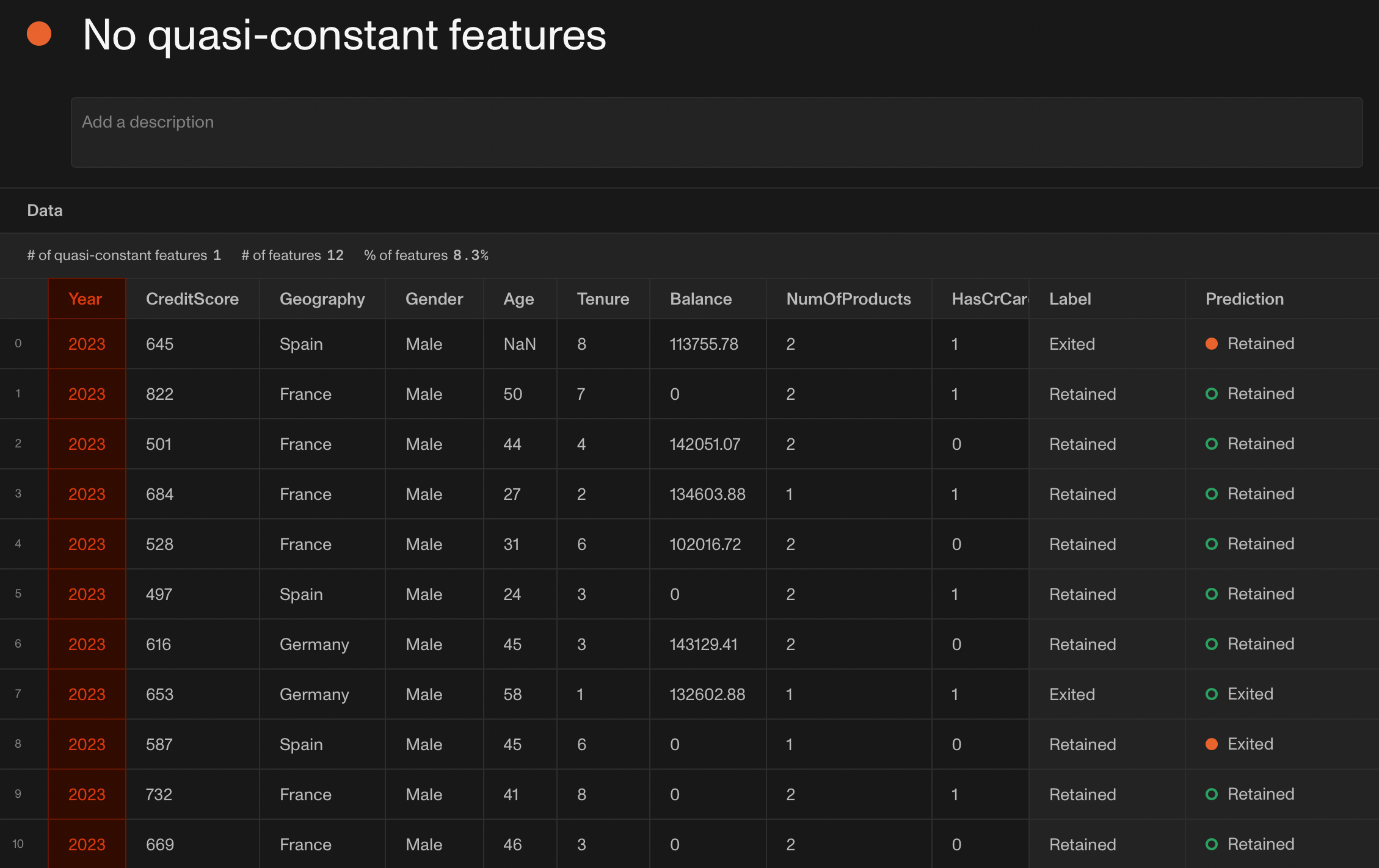
(Screenshot from Openlayer)
Conclusion
Data integrity is a cornerstone of successful ML models. Neglecting it can lead to biased predictions, poor performance in specific subpopulations, and misleading evaluation metrics, ultimately undermining the trustworthiness and effectiveness of ML applications.
We have highlighted how simple and effective guardrails can be put in place to prevent the introduction of integrity issues. These are just a few among many possibilities. Keep reading our blog posts on the topic to learn more.