How to generate synthetic data for machine learning projects
Solving the data gap
Machine learning models, especially deep neural networks, are trained using large amounts of data. However, for many machine learning use cases, real-world data sets do not exist or are prohibitively costly to buy and label. In such scenarios, synthetic data represents an appealing, less expensive, and scalable solution.
Additionally, several real-world machine learning problems suffer from class imbalance—that is, where the distribution of the categories of data is skewed, resulting in disproportionately fewer observations for one or more categories. Synthetic data can be used in such situations to balance out the underrepresented data and train models that generalize well in real-world settings.
Synthetic data is now increasingly used for various applications, such as computer vision, image recognition, speech recognition, and time-series data, among others. In this article, you will learn about synthetic data, its benefits, and how it is generated for different use cases.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
What is synthetic data?
Synthetic data is a form of data augmentation that is commonly used to address overfitting deep learning models. It’s generated with algorithms as well as machine learning models to have similar statistical properties as the real-world data sets. For data-hungry deep learning models, the availability of large training data sets is a massive bottleneck that can often be solved with synthetic data.
Additionally, synthetic data can be used for myriad business problems where real-world data sets are missing or underrepresented. Several industries—like consumer tech, finance, healthcare, manufacturing, security, automotive, and robotics—are already benefiting from the use of synthetic data. It helps avoid the key bottleneck in the machine learning lifecycle of the unavailability of data and allows teams to continue developing and iterating on innovative data products.
For example, building products related to natural language processing (NLP), like search or language translation, is often problematic for low-resource languages. Synthetic data generation has been successfully used to generate parallel training data for training deep learning models for neural machine translation.
Generating synthetic data for machine learning
There are several standard approaches for generating synthetic data. These include the following:
- Statistical approaches based on sampling from the source data distribution
- Deep neural network–based methods such as variational autoencoders and generative adversarial networks
The choice of methods for synthetic data generation depends on the type of data to be generated, with statistical methods being more common for numerical data and deep learning methods being commonly used for unstructured data like images, text, audio, and video. In the following sections, you’ll learn more about the different types of synthetic data and then explore some techniques for generating it.
Types of synthetic data
Synthetic data can be classified into different types based on their usage and the data format. Generally, it falls into one of two categories:
- Partially synthetic data, where only a specific set of the training data is generated artificially
- Fully synthetic data, where the entire training data set consists of synthetic data
Partially synthetic data finds its application in use cases where sensitive data needs to be replaced in the original training data set. Fully synthetic data sets are used in domains like finance and healthcare, where privacy and compliance concerns restrict the use of original data.
Popular types of synthetic data, classified according to the data type, include the following:
- Synthetic text
- Synthetic media including images, audio, and video
- Synthetic time-series data
- Synthetic tabular data
Synthetic text finds its use in applications like language translation, content moderation, and product reviews. Synthetic images are used extensively for purposes like training self-driving cars, while synthetic audio and video data is used for applications including speech recognition, virtual assistants, and digital avatars. Synthetic time-series data are used in financial services to represent the temporal aspect of financial data, like stock price. Finally, synthetic tabular data is used in domains like e-commerce and fraud.
Techniques for generating synthetic data
Generating synthetic data can be very simple, such as adding noise to data samples, and can also be highly sophisticated, requiring the use of state-of-the-art models like generative adversarial networks. In this section, you’ll review two chief methods for generating synthetic data for machine learning and deep learning applications.
Statistical methods
In statistics, data samples can be assumed to be generated from a probability distribution with certain characteristic statistical features like mean, variance, skew, and so on. For instance, in the case of anomaly detection, one assumes that the nonanomalous samples belong to a certain statistical distribution while the anomalous or outlier samples do not correspond to this data distribution.
Consider a hypothetical machine learning example of predicting the salaries of data scientists with certain years of experience at top tech companies. In the absence of real-world salary data, which is a topic considered taboo, synthetic salary data can be generated from a distribution defined by the few real-world salary public reports on platforms like Glassdoor, LinkedIn, or Quora. This can be used by recruiters and hiring teams to benchmark their own salary levels and adjust the salary offers to new hires.
Deep learning-based methods
As the complexity of the data increases, statistical-sampling-based methods are not a good choice for synthetic data generation. Neural networks, especially deep neural networks, are capable of making better approximations of complex, nonlinear data like faces or speech. A neural network essentially represents a transformation from a set of inputs to a complex output, and this transformation can be applied on synthetic inputs to generate synthetic outputs. Two popular neural network architectures for generating synthetic data are variational autoencoders and generative adversarial networks, which will be discussed in detail in the next sections.
Variational autoencoders
Variational autoencoders are generative models that belong to the autoencoder class of unsupervised models. They learn the underlying distribution of a data set and subsequently generate new data based on the learned representation.
VAEs consist of two neural networks: an encoder that learns an efficient latent representation of the source data distribution and a decoder that aims to transform this latent representation back into the original space. The advantage of using VAEs is that the quality of the generated samples can be quantified objectively using the reconstruction error between the original distribution and the output of the decoder. VAEs can be trained efficiently through an objective function that minimizes the reconstruction error.
VAEs represent a strong baseline approach for generating synthetic data. However, VAEs suffer from a few disadvantages. They are not able to learn efficient representations of heterogeneous data and are not straightforward to train and optimize. These problems can be overcome using generative adversarial networks.
Generative adversarial networks
GANs are a relatively new class of generative deep learning models. Like VAEs, GANs are based on simultaneously training two neural networks but via an adversarial process.
A generative model, G, is used to learn the latent representation of the original data set and generate samples. The discriminator model, D, is a supervised model that learns to distinguish whether a random sample came from the original data set or is generated by G. The objective of the generator G is to maximize the probability of the discriminator D, making a classification error. This adversarial training process, similar to a zero-sum game, is continued until the discriminator can no longer distinguish between the original and synthetic data samples from the generator.
GANs originally became popular for synthesizing images for a variety of computer-vision problems, including image recognition, text-to-image and image-to-image translation, super resolution, and so on. Recently, GANs have proven to be highly versatile and useful for generating synthetic text as well as private or sensitive data like patient medical records.
Tutorial
In this section, you will go through a brief tutorial to generate synthetic images using deep learning methods. Specifically, two images will be segmented using a pre-trained neural network module. Then the images will be annotated to describe the objects that the model was able to identify. There are many use cases for this technique, including identifying specific objects or separating images for other purposes.
To achieve the results described above, you can use a number of different frameworks. However, for the purposes of this tutorial, you will use PixelLib and PyTorch. PyTorch is an open-source machine learning framework that is similar to TensorFlow in many ways. It has a rich ecosystem of tools and libraries specialized in computer vision, NLP, and more. PixelLib, on the other hand, is a library designed to perform image segmentation using only few lines of code. An advantage of these tools is that they are written in Python, which makes them easy to use for development.
Note: If you want to clone the project used in this tutorial and follow along in your own editor, you can access the GitHub repository here.
Prerequisites
To follow this tutorial, you’ll need the following:
- A local machine or VM (recommended) running Ubuntu 20.04-LTS.
- At least 4GB of RAM and 4GB of swap space, assuming you’re using a VM. To learn more about increasing swap in Ubuntu, check out this thread.
- A non-root user with
sudopermissions and SSH access to the remote server (VM only).
Note: Although both PyTorch and PixelLib can run on macOS and Windows, it is best to use the recommended setup with Ubuntu 20.04-LTS, as it minimizes compatibility issues between Python libraries. Furthermore, the model that will be used in this tutorial is currently only available for Linux.
Create a virtual environment
The best practice when working with projects written in Python is to use isolated virtual environments. This ensures that you won't break the base Python compiler your OS uses. That said, in this tutorial, you will use venv since it is one of the most popular virtual environment packages for Python. Additionally, pip will be installed to handle all dependencies and libgl1 will be used to render the images.
- Install
venv,pip, and the rest of the global dependencies by running the following command:
$ sudo apt update && sudo apt install python3-pip python3-venv libgl12. Update pip to the latest version:
$ python3 -m pip install --upgrade pip3. Create a directory for the virtual environment. This example will create a hidden directory called .pytorch, but you can use any name you’d like.
$ mkdir .pytorch4. Create the virtual environment using venv. In this example, the name of the environment will also be pytorch.
$ python3 -m venv .pytorch/pytorch5. Activate the virtual environment by running the following command:
$ source .pytorch/pytorch/bin/activateYou will know that the virtual environment is enabled if you see its name preceding the path on the command line, like this:
(pytorch) damaso@localhost:~$ Install PyTorch and PixelLib
Now that you have your virtual environment up and running, you can safely install all the necessary dependencies using pip.
1. Start by installing PyTorch using the following command:
$ python3 -m pip install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cpu
Although it seems trivial, this step is one of the most crucial. It's vitally important that you use specific versions of each package depending on your OS and hardware. Fortunately, there is a handy configurator at pytorch.org that can be used to generate the proper code:
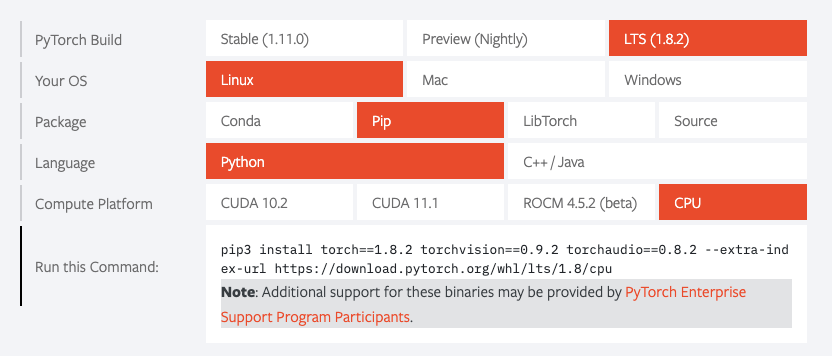
2. Install pycocotools, a Python API library that assists in loading, parsing, and visualizing image annotations in COCO:
$ python3 -m pip install pycocotools3. Install the PixelLib library by running the following command:
$ python3 -m pip install pixellibAt this point, you have a basic framework ready to generate synthetic images. If you haven’t already, go ahead and clone the following repository with the sample code that will be used in this tutorial:
$ git clone https://github.com/Damaso-DD/Generate-Synthetic-Data-ML.gitOnce cloned, you will notice a structure like the following:
.
├── input_images
│ ├── eliott-reyna-jCEpN62oWL4-unsplash.jpg
│ └── pexels-sebastian-voortman-214576.jpg
├── LICENSE
├── models
│ └── download_here
├── output_images
│ └── images_here
├── pytorch.py
└── README.mdA few notes about this structure:
input_imagesis the directory where the raw images will be stored. For this tutorial, two images will be used.output_imagesis the directory where the processed images will be stored.modelsis the directory where the pre-trained models used by PixelLib will be saved. For this tutorial, only PointRend will be used.pytorch.pyis the code that processes the images.
Before continuing, you’ll have to download PointRed in the respective directory. To do this, navigate to the models directory and run the following code:
$ wget https://github.com/ayoolaolafenwa/PixelLib/releases/download/0.2.0/pointrend_resnet50.pkl
Now all that’s left is to analyze the code of pytorch.py and process the images.
Delving into object segmentation
As mentioned above, one of the most common use cases for ML is to generate synthetic images from one or more base images. In that sense, the framework you have installed allows real-time instance segmentation of objects in images and videos using just a few lines of code.
To illustrate this point, open the file pytorch.py using your preferred text editor. You will see the following code:
import pixellib
from pixellib.torchbackend.instance import instanceSegmentation
ins = instanceSegmentation()
ins.load_model("models/pointrend_resnet50.pkl")
ins.segmentImage("input_images/eliott-reyna-jCEpN62oWL4-unsplash.jpg", show_bboxes=True, output_image_name="output_images/output-pytorch-01.jpg")
ins.segmentImage("input_images/pexels-sebastian-voortman-214576.jpg", show_bboxes=True, output_image_name="output_images/output-pytorch-02.jpg")Let's analyze what the code shown above does:
- Lines 1-2. Both the
pixelliblibrary and theinstanceSegmentationclass are imported for later use. - Line 4. For convenience, the
insvariable is declared to abbreviate the code that follows. - Line 5. The model to be used for image segmentation is invoked. In this case, it is PointRed.
- Lines 6-7. The
segmentImagefunction is called to perform the segmentation of objects in the images at theinput_imageslocation. Additionally, it's indicated that the processed images should be saved at the locationoutput_images. Finally, theshow_bboxes=Trueparameter tells PixelLib to enclose each object in a box and annotate it with its respective ID.
Before running the code, take a look at the raw images in the input_images directory. Both images were chosen to test PixelLib's ability to correctly segment and identify objects and people in each image.


Now, go to the root directory where pytorch.py is located, and with the virtual environment still activated, run the code:
$ python3 pytorch.pyYou will see an output similar to the following:
$ (pytorch) damaso@localhost:~/Generate-Synthetic-Data-ML$ python3 pytorch.py
$ The checkpoint state_dict contains keys that are not used by the model:
proposal_generator.anchor_generator.cell_anchors.{0, 1, 2, 3, 4}Next, take a look at the rendered images stored in the output_images directory:


As you can see, with just a few lines of code, you were able to generate annotated images that identify each person with a different color, as well as objects that include a bottle and cars in the first image, and a backpack in the second image. The outlined objects can then be placed on a different background in order to create a synthetic image.
The potential of PyTorch and PixelLib goes far beyond what has been shown here. For more information on additional parameters, check out PixelLib’s documentation.
Other examples of synthetic-image generation include state-of-the-art text-to-image deep learning models such as DALLE-2 and Imagen. These models take a text input from the user and generate a synthetic image corresponding to the user description.
Synthetic data generation with Openlayer
Openlayer is a machine learning debugging workspace that helps individual data scientists and enterprise organizations alike to track and version models, uncover errors, and generate synthetic data. It is primarily used to augment underrepresented portions or classes in the original training data set. Synthetic data is generated from existing data samples, and data-augmentation tests are conducted to verify whether the model’s predictions on the synthetic data are the same as for the original data.
Conclusion
In this article, you learned about synthetic data for machine learning and deep learning applications. In the absence of real-world data, as well as other pertinent issues like privacy concerns or the high costs of data acquisition and labeling, synthetic data presents a versatile and scalable solution. Synthetic data has found mainstream acceptance in a number of domains and for a variety of data types, including text, audio, video, time series, and tabular data.
You explored these different types of synthetic data and the various methods for generation. These include statistical approaches as well as neural network–based methods like variational autoencoders and generative adversarial networks. Then you walked through a brief tutorial for generating synthetic data using deep learning methods. Finally, you saw the utility of third-party synthetic data generation products such as Openlayer, which can help companies rapidly scale their synthetic data requirements and accelerate model development and deployment.
* A previous version of this article listed the company name as Unbox, which has since been rebranded to Openlayer.


