The challenge of becoming a full-stack data scientist
Mastering the full ML lifecycle
In the past two decades, large and small companies alike have collected data in increasingly large volumes. Their data scientists are in charge of turning that data into something valuable for use in improved decision-making, predictive models, AI-driven products and services, and the like.
Although new tools and frameworks (like DataOps) have seen the light of day, many organizations still experience difficulties deploying their data products. One solution to that problem is to hire a full-stack data scientist (FSDS). They combine data engineering, data science, and MLOps skills to build end-to-end data solutions.
In this article, you’ll learn what a full-stack data scientist does, why these scientists are so valuable, and what it takes to become one.
Be the first to know by subscribing to the blog. You will be notified whenever there is a new post.
The full-stack data scientist
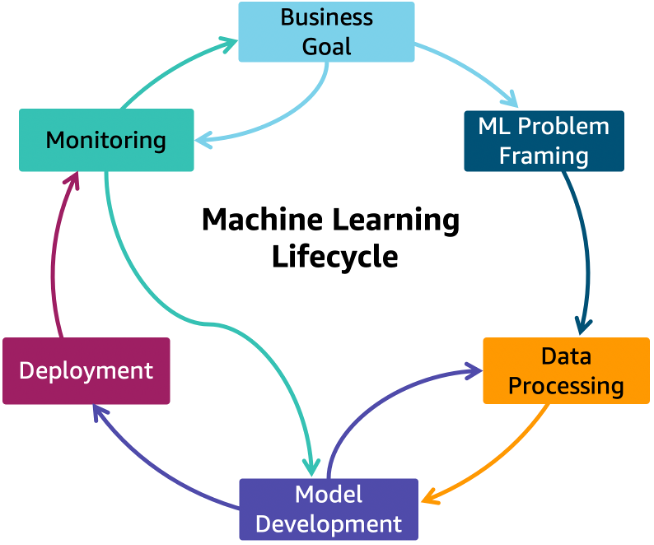
Typically, data scientists spend their days writing code for exploratory analysis and developing predictive models. To work productively and for their work to have an impact, they have upstream and downstream dependencies:
- Upstream, data scientists need access to a data repository (such as a data lake or warehouse) that holds their training data. For many organizations, this isn’t self-evident. Getting data from source systems (such as transactional databases or SaaS tools) into a data warehouse requires daily work and maintenance by data engineers.
- Downstream, they rely on the work of IT or ML engineers to take their models out of Jupyter notebooks into production. Too often, industrializing models is an insurmountable hurdle, causing many machine learning products never to leave the experimental phase.
Enter the full-stack data scientist. Instead of relying on the efforts of multiple colleagues upstream and downstream, FSDSs have skills that span the entire machine learning lifecycle. They build, maintain, and fix data pipelines upstream and deploy and monitor models downstream.
Here’s an overview of the possible activities they might be involved in:
- Data collection: extracting data from production databases, implementing tracking scripts in websites and apps, configuring sensors, and so on;
- Data engineering: building and maintaining data pipelines into data lakes or warehouses;
- Exploratory data analysis: exploring, cleaning, and visualizing data and performing statistical tests;
- Model development and error analysis: developing models with machine learning techniques and evaluating their performance in real-world scenarios;
- Model deployment: deploying their models as real-time APIs or as batch predictions;
- Model monitoring: continuous monitoring of model performance, preventing model drift, and retraining.
Working with full-stack data scientists instead of relying upon multiple individuals in specialized roles has several benefits for many organizations.
First of all, because FSDSs work on all steps of the ML lifecycle, they are aware of what’s happening up and downstream. When they encounter issues, they can tackle them holistically. This is in contrast with specialists, who are often unaware of the intricacies outside their scope. Many times, this requires them to convene additional meetings or calls in order to solve a problem.
FSDSs who work end to end tend to spend less time in meetings simply because there is less need for coordination or for clarifying each role’s scope. They can decide on technical specifics all by themselves because no one else but themselves consumes their work in the subsequent step downstream.
Furthermore, on projects with a lot of blocking factors upstream or downstream, FSDSs are typically very efficient due to the wide applicability of their skills. If the development of a model is stalled for whatever reason, FSDSs can minimize idle time by assisting other colleagues or developing something that has been sitting in the backlog, often outside the scope of a traditional data scientist.
These benefits result in faster prototyping, faster end-to-end development, and often lower costs, as opposed to hiring for multiple roles.
The skills of a full-stack data scientist
It should be clear by now that an FSDS’s skills can be deployed anywhere in the ML lifecycle—it’s no wonder organizations are willing to pay well to hire people with such versatile skill sets. In this section, you’ll find an overview of the hard skills you’ll need to master to call yourself a full-stack data scientist.
Data science
Skills: coding, statistics, machine learning
First of all, you need to know data science. This means you need to be able to code, preferably in Python as it’s the lingua franca throughout the ML lifecycle. On top of that, you need to have a solid knowledge of statistics: descriptive stats, probability and distributions, bias/variance trade-off, correlation, and sampling. Finally, to build your own algorithms, you’ll need to know supervised and unsupervised machine learning techniques.
Data analysis
Skills: SQL, data exploration, visualization, communication
A lot of work that data scientists do today was once the task of data analysts: slicing the data to discover valuable patterns. First of all, you need to be able to retrieve the data via SQL. Furthermore, you should be able to work with data exploration and visualization tools such as Microsoft Excel, Tableau, Power BI, Mode, Superset, and the like. Finally, communication with stakeholders about data products, problems, and opportunities is an important skill that’s often overlooked, but the ability to lay out a problem and a data solution for the less data-savvy is extremely valuable.
Data collection
Skills: JavaScript, tag management
Data collection and its methods depend a lot on the sector you’re a part of. For example, a lot of effort is spent on collecting behavioral data from customers interacting with apps, websites, and other digital interfaces. If you want to get involved, you should learn JavaScript and tag management technology such as Tealium or Google Tag Manager.
Data analytics engineering
Skills: building DAGs and data pipelines, data quality and testing, Spark
FSDSs, like data engineers, take the data from its raw form to a processed form, ready for consumption. Although there are standardized approaches for many data sources and destinations, there’s often a lot of creativity involved due to technical legacy or compliance limitations. Skills required include building DAGs using Airflow, Prefect, or Dagster and setting up ETL or ELT pipelines using Beam, Singer, or dbt. You’ll also run into Spark when data gets really big and Kafka if you’re working with streaming data. Developing data-quality assertions and writing tests will also come in handy.
Machine learning engineering
Skills: building APIs, containerization, cloud, model monitoring
To turn data into data products, you’ll need more than just data engineering skills. Downstream, you also need to be able to put models into production, which is where ML engineering comes in. It’s essential that you know how APIs work and how you can containerize them (Docker) and deploy them in the cloud via Kubernetes (or an abstraction of it, such as Kubeflow or SageMaker). It’s also an added bonus if you know how to monitor models and detect model drift.
Finally, the filling between all these tools and skills is code, data, and model versioning. If you’re serious about becoming a full-stack data scientist, you should understand the basics of Git, such as forking, branching, and pull requests.
Challenges and getting started
If you’re overwhelmed, that’s perfectly normal. Data science and data engineering are relatively new professions. There are many tools and techniques out there, and there aren’t many agreed-upon standards. A data scientist in one organization might be doing things completely differently from one in another organization.
Being a full-stack data scientist doesn’t mean that you need to be an expert in each of these tools, but it does mean that you should be widely employable and able to adapt to changing practices and standards quickly.
Below, you’ll find some helpful advice for acquiring most of these skills.
Online courses
Typically, online courses aren’t the fastest way to learn how to get a specific task done. That’s because they spend time explaining best practices and side information you don’t necessarily need. However, if you’re entirely new to a field, building up a solid base is a path worth considering. It’ll help you put into context what you’re learning, which might save you a lot of time afterward. Learning platforms like Udemy, Coursera, EdX, and LinkedIn Learning offer very cheap online courses. If you’re worried about the money, know that these are excellent investments in your career if you complete them. Finally, if you have no idea where to get started, consider this learning path for data engineering skills or one of Coursera’s data science learning paths.
Home projects
If you’re currently in a job that’s completely unrelated to data and analytics, consider working on side projects at home. Not only is this a great way to broaden your skillset, but it will also help you build up your personal portfolio. Anything you build locally is free. However, if you’re serious about acquiring skills from within the field of data engineering, consider developing and deploying your projects in the cloud (at AWS, Azure, GCP, or DigitalOcean). This way, you’ll expose yourself to settings and situations that you might encounter in a professional environment.
Papers, blogs, and newspapers
Especially in the field of data science, a lot of scientific and technological research is being done. Instead of trying to keep track of all the latest research, consider reading classical papers. You might expect papers with a lot of mathematical equations, but that’s often not the case.
ArXiv is a popular place for data science papers, but you’ll be lost if you don’t know what you’re looking for. This repository on MLOps and this one on data science are two great places to start. You could also subscribe to Two Minute Papers. If you like newsletters, try Data Engineering Weekly, Data Elixir, or The Batch.
Online communities
There is an abundance of self-proclaimed communities for data professionals and hobbyists. However, not all of them are very active, nor do they contain a lot of members that are worth following. Noteworthy Slack channels include Locally Optimistic, the dbt Community, and #measure.
Final thoughts on becoming a full-stack data scientist
In this article, you’ve learned what a full-stack data scientist is and why they are so useful. If you want to become one yourself, here are a few final pieces of advice.
First, don’t expect that the journey to becoming a full-stack data scientist will be easy. It requires a lot of time and effort, and you’ll most likely run into your personal limits. To keep learning, make sure to push beyond your comfort zone:
- Try to do things differently every time you work on a new personal project.
- Try to break things.
- Try to find the root cause of an error instead of applying a Stack Overflow answer.
Second, how long it will take to become a full-stack data scientist depends on three things, two of which you have control over:
- Your background: You can’t control what you already know or what your previous experience is. If your background is in software engineering or data analysis, you’ll have a head start, as you might already have interacted with specific tools or techniques.
- Your spare time: There are only twenty-four hours in a day, but how much time you reserve for educating yourself is entirely up to you.
- Your professional situation: Some jobs could enable you to put your newly acquired knowledge into practice. If you’re in digital marketing, finance, or operations, you probably have access to a lot of currently underused data.
Whatever your situation is, the opportunity to further develop your skill set toward becoming an FSDS is at your fingertips. Don’t hesitate to consult one of the many resources discussed above to get started!


